
Understanding Bias
Emerging big data sources unlike traditional surveys come with their own biases, which could be distinct across space, time and socio-demographics. This is because, these data sources are more of a convenience sample heavily influenced by the purpose of software application generating it, from which it is derived. Thus, it makes them more to be representative of the specific group of population than overall population of a region. Our experience working with diverse data sources and surveys have led us to develop methods to control for such biases.
Data Imputation
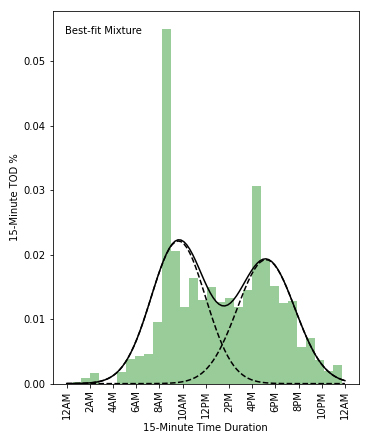
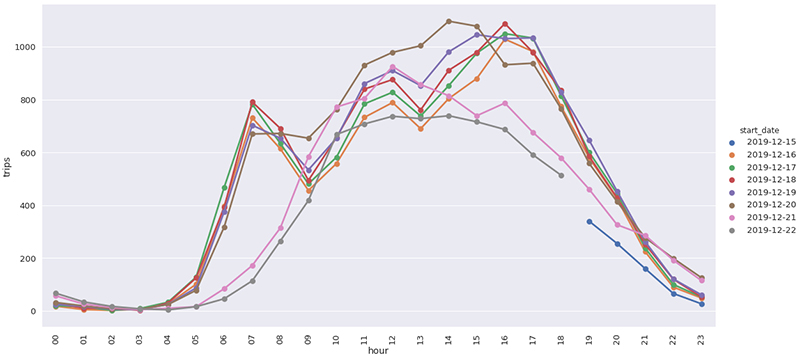
Further, even though a sample may originate as big data, only small number of vehicles/devices contribute to a sample for a link or zone being investigated. For example, the time of day distribution (say 15 minute period of a day for a given roadway link) of the sample can provide important information on when traffic peaks on a given link. However, the relative height of the peaks and the dispersion (or shape) around the peaks may not representative. We can estimate a smoothed distribution while keeping the peak time information. To this effect one could employ appropriate machine learning techniques such as Gaussian Mixture Model (GMM) to impute missing values.
Big Data Analytics
This being said, emerging data sources add significant value, with it being available far more frequently and at much finer resolution compared to surveys. Importantly, in aggregate, a well sampled and expanded passive data could provide a precise representation of existing condition. As expected, to achieve the above, one needs significant computing resources and expertise. To address this need, our team has put together a data processing/analysis pipeline synthesizing historical travel surveys, passive big data, and other transportation datasets by adopting a data lake solution. It consists of three services from the Amazon Web Service (AWS): S3 (storage), Glue (catalog/data discovery), and Athena (distributed query engine). This allows us to be flexible to analyze, visualize and prototype methods using advanced statistical and machine learning algorithms using R, Python, Apache Spark etc.
Utilizing Open Source Tools
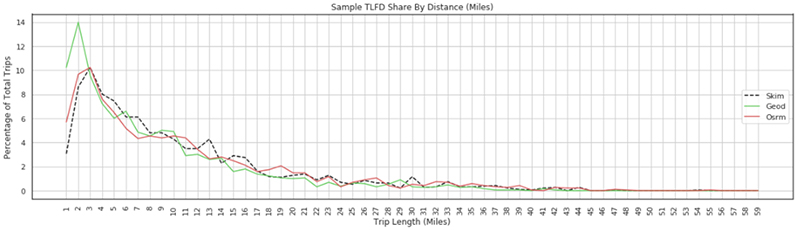
For example, we evaluated alternative network assignment procedures as part of our effort to estimate commercial vehicle miles traveled from passive data using our cloud services. Specifically, we examined the potential to use Open Source Routing Machine (OSRM) as an alternative to using skims from travel demand model runs. This is because, our legacy method using skims required significant time and resources. The intent here was to evaluate whether OSRM yielded a similar trip length distribution as that produced using skims from travel demand model runs. Our analysis revealed OSRM based assignment to be not significantly different, very likely due to underlying commercial travel behavior which predominately involves a fixed schedule and route unlike passenger travel.
For More Information
Jisung Kim(979) 317-2600
[email protected]
or
Vijay Sivaraman
(813) 389-8224
[email protected]